35
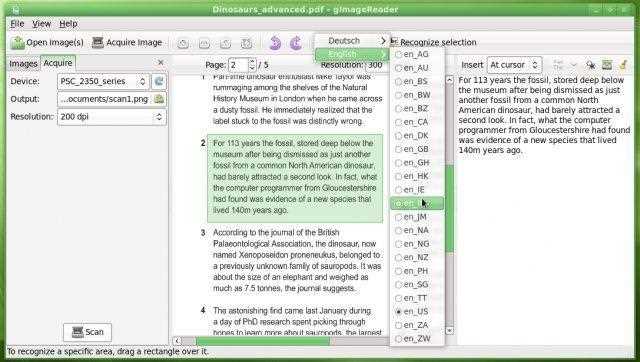
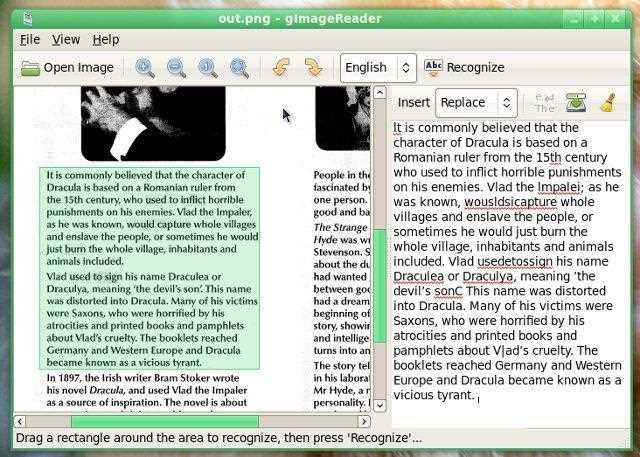
gImageReaderは、Tesseract OCRエンジンのシンプルなGtk / Qtフロントエンドです。機能:-ディスク、スキャンデバイス、クリップボード、スクリーンショットからPDF文書と画像をインポート-複数の画像と文書を一度に処理-手動または自動認識領域定義-プレーンテキストまたはhOCR文書を認識-すぐ横に表示される認識されたテキスト画像-スペルチェックを含む認識されたテキストの後処理-hOCRドキュメントからPDFドキュメントを生成
カテゴリー
ライセンスのあるすべてのプラットフォームでのGImageReaderの代替
1
0
norpaOCR
スキャン、PDF、バーコードからテキストを抽出するためのオールインワンアプリケーション。SDKが追加で利用可能。利用可能なクラウドソリューション。ボリュームに依存しないライセンス。インテグレーターは歓迎します。
- 有料アプリ
- Windows
- Self-Hosted
0
0
SmarterBackups
あらゆる規模の企業向けのエンタープライズレベルのクラウドストレージおよびデータバックアッププラットフォーム。効率的なビジネス運営を促進するための組み込みの人工知能および生産性ツール。
- 有料アプリ
- Web
- Self-Hosted
0
0
0
0
0
0
OCR Text Detection Tool
デバイスからダウンロードされた、またはスナップショットで撮影された画像ファイルからテキストを正確かつ高速に検出します。また、PDFのテキスト検出と、114の異なる言語でのテキストベースの手書き検出およびテキスト翻訳もサポートしています。