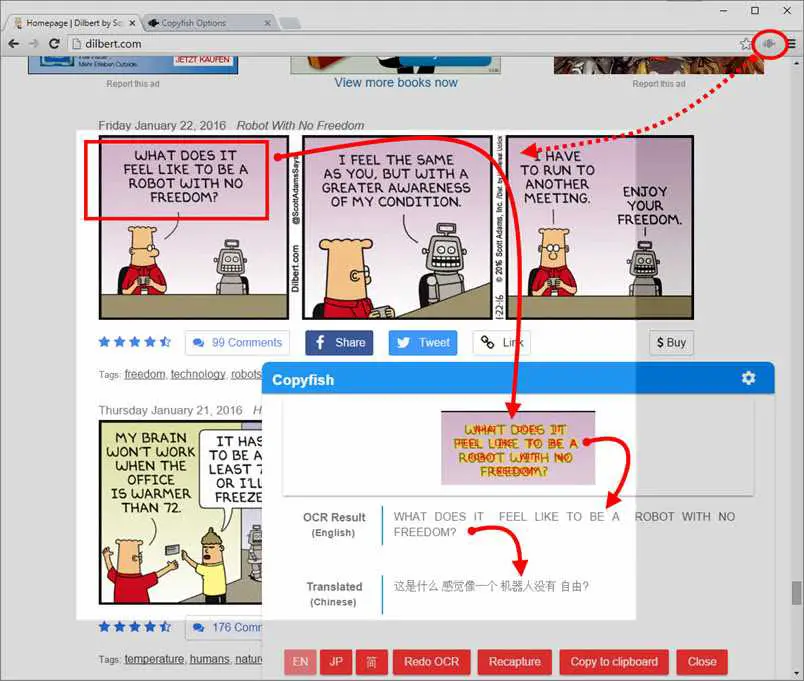
任意のWebサイトの画像/ビデオ/ PDFからテキストを抽出して翻訳します。画像からテキストを抽出する一般的な理由は、テキストをグーグル検索、保存、電子メール送信、または翻訳する場合です。これまで、唯一の選択肢はテキストを再入力することでした。Copyfishは非常に高速です。(小さな)テキストの読み取りに問題がある私たちにとって、Copyfishは画像内のテキストにスクリーンリーダーを使用する機能を提供します。「画像」には、写真、チャート、図、スクリーンショット、PDFドキュメント、コミック、ダイアログボックス、ミーム、スキャン、Flash、YouTubeムービーなど、あらゆる種類があります。
copyfish
ウェブサイト:
https://a9t9.com/copyfish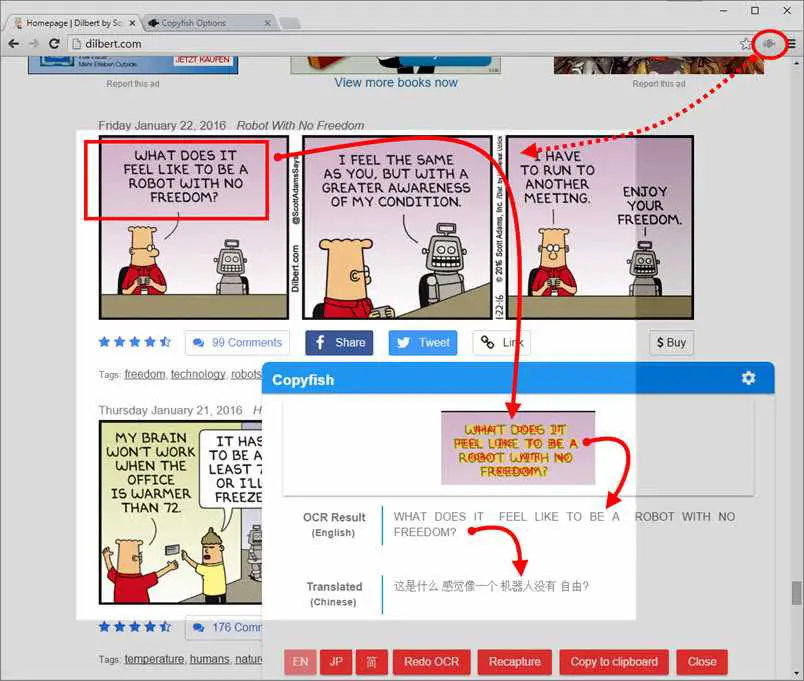
商用ライセンスを使用するすべてのプラットフォーム用のCopyFishの代替
116
ABBYY FineReader
ABBYY FineReaderは、比類のないテキスト認識精度と変換機能を提供するOCRソフトウェアであり、ドキュメントの再入力と再フォーマットを実質的に排除します。テキスト認識では、最大190の言語がサポートされています。
22
ABBYY Screenshot Reader
スクリーンショットリーダーは、PC画面上の任意の領域からテキストと画像をキャプチャし、そこからテキストを抽出するか、単に画像として保存するためのスマートなOCRスクリーンショットアプリケーションです。
- 有料アプリ
- Windows
13
Scanitto Pro
Scanitto Proは、イメージスキャン、ダイレクトプリントおよびコピー、基本的な編集およびテキスト認識(OCR)用のWindowsベースのソフトウェアアプリケーションです。
- 有料アプリ
- Windows
12
TextGrabber
ABBYY TextGrabberは、選択したテキストまたはQRコードを事実上あらゆる印刷物から簡単かつ迅速にスキャン、翻訳、保存します。
11
3
2
Anyline
Anylineは、開発者がOCRに関する知識がなくてもテキスト認識アプリを構築できるモバイルテキスト認識SDKです。
2
Kleptomania
Kleptomaniaでは、ワードプロセッサのデータ列やエラーメッセージなど、マウスで強調表示できない領域を含め、画面上の任意の場所でテキストを選択できます...
- 有料アプリ
- Windows
2
OmniPage Cloud Service
OmniPageクラウドサービスは、OmniPage Capture SDK上に構築されたクラウドコンピューティングプラットフォームです。
- 有料アプリ
- Web
1
1
Boxoft Screen OCR
Boxoft Screen OCRは、画面上の任意の領域を抽出し、すべての文字を認識し、TXTファイルとして保存するのに役立つ高速で使いやすいソフトウェアです。価格:27 USD。
- 有料アプリ
- Windows
0
