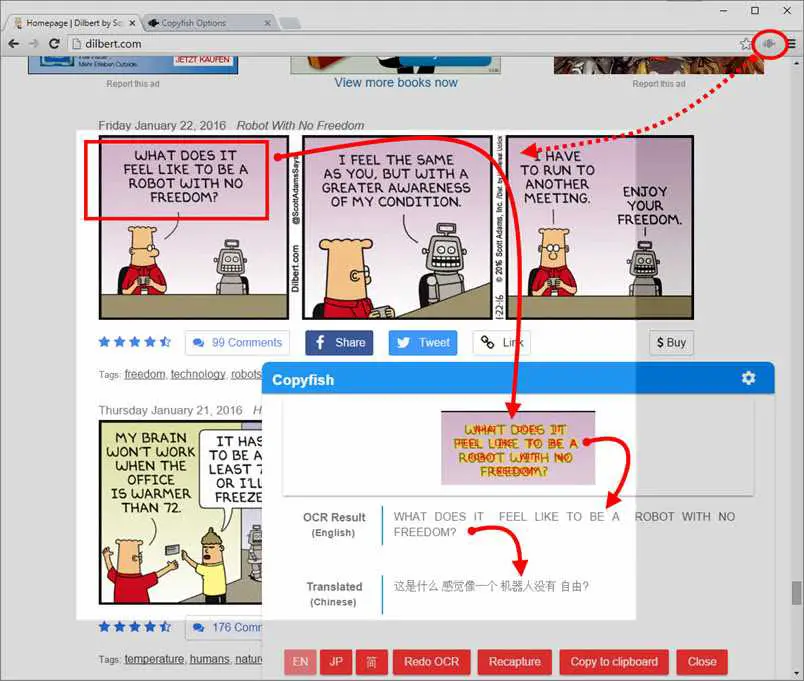
任意のWebサイトの画像/ビデオ/ PDFからテキストを抽出して翻訳します。画像からテキストを抽出する一般的な理由は、テキストをグーグル検索、保存、電子メール送信、または翻訳する場合です。これまで、唯一の選択肢はテキストを再入力することでした。Copyfishは非常に高速です。(小さな)テキストの読み取りに問題がある私たちにとって、Copyfishは画像内のテキストにスクリーンリーダーを使用する機能を提供します。「画像」には、写真、チャート、図、スクリーンショット、PDFドキュメント、コミック、ダイアログボックス、ミーム、スキャン、Flash、YouTubeムービーなど、あらゆる種類があります。
ウェブサイト:
https://a9t9.com/copyfish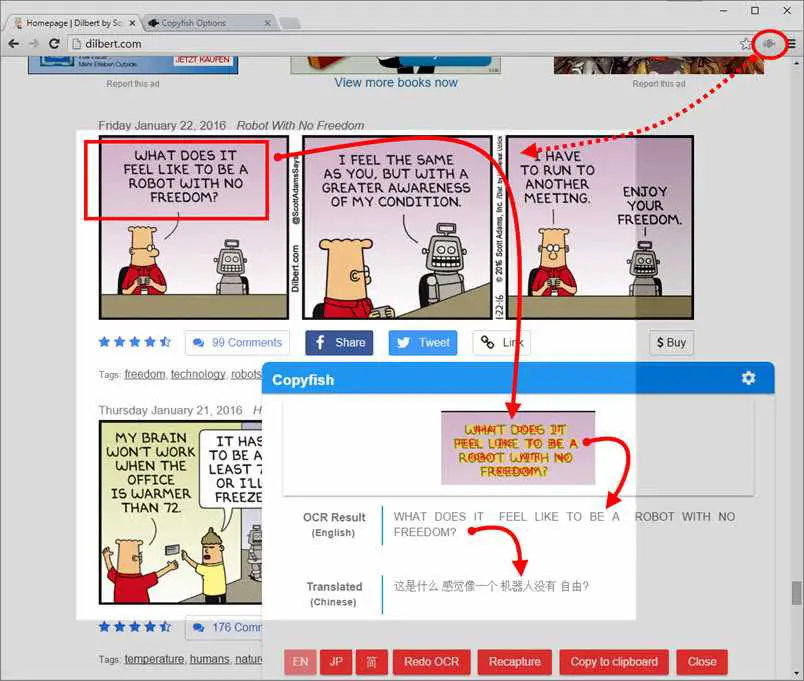
LinuxのCopyFishの代替
13
9
5
5