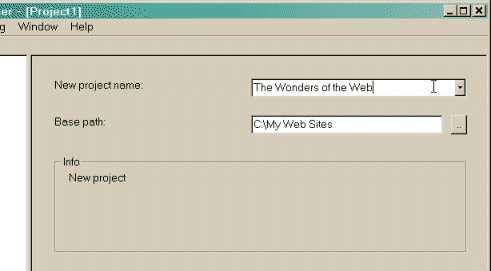
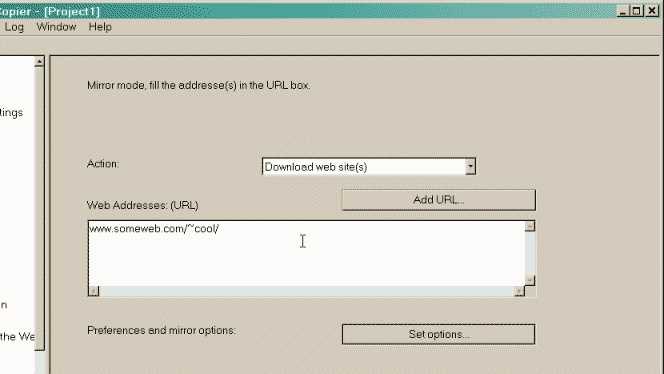
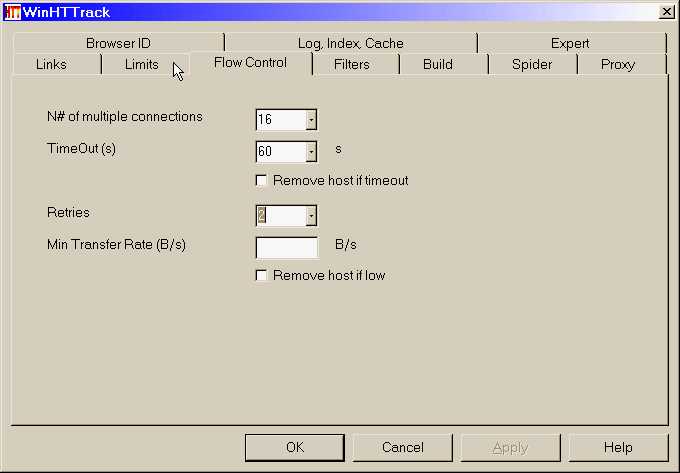
HTTrackは無料(GPL、libre / freeソフトウェア)で使いやすいオフラインブラウザーユーティリティです。インターネットからローカルディレクトリにWorld Wide Webサイトをダウンロードし、すべてのディレクトリを再帰的に構築して、HTML、画像、およびその他のファイルをサーバーからコンピューターに取得できます。HTTrackは、元のサイトを相対リンク構造に配置します。ミラーリングされたWebサイトのページをブラウザーで開くだけで、オンラインで閲覧しているように、リンクからリンクまでサイトを閲覧できます。HTTrackは、既存のミラーサイトを更新し、中断したダウンロードを再開することもできます。HTTrackは完全に構成可能で、統合されたヘルプシステムを備えています。WinHTTrackはHTTrackのWindows 9x / NT / 2000 / XP / Vistaリリースで、Linux / Unix / BSDリリースはWebHTTrackです。...
ウェブサイト:
https://www.httrack.comカテゴリー
LinuxのHTTrackの代替
358
85
34
14
PageArchiver
PageArchiver(以前は "Scrapbook for SingleFile"と呼ばれていました)は、オフラインで読むためにWebページをアーカイブするのに役立つChrome拡張機能です。主な機能は次のとおりです。
14
12
11
HTTP Ripper
HTTP Ripperは、Webからコンテンツをリッピングするツールです。例*ビデオサイトから映画をダウンロード*お気に入りのバンドのウェブサイトの音楽をダウンロード
7
WebScrapBook
高度にカスタマイズ可能な構成でWebページを忠実にキャプチャするブラウザー拡張機能。
3